1. ndarray란?
: n차원(Dimension) 배열(Array) 객체
2. ndarray 생성
import numpy as np
array1 = np.array([1,2,3])
array2 = np.array([[1,2,3], [2,3,4]])
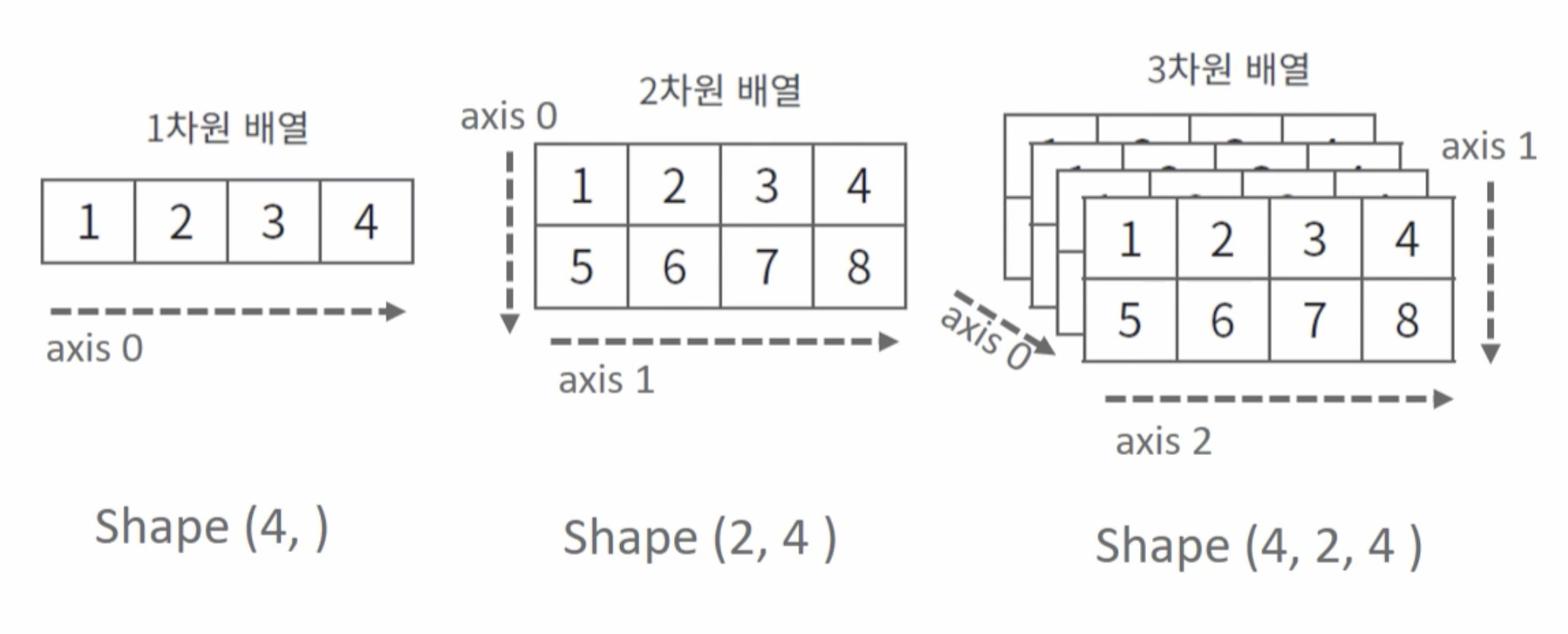
3. ndarray 형태(Shape)와 차원
: 1차원, 2차원, 3차원 ...
| array | 차원 | Shape |
| [1,2,3] | 1차원 | (3,) |
| [[1,2,3], [4,5,6]] | 2차원 | (2,3) |
- Shape는 "(행, 열)" 형태로 구분된다.
- 1차원의 경우 (3,) 처럼 쉼표로 끝난다.
- Shape, 차원 확인 방법
# Shape 확인
ndarray.shape
# 차원확인
ndarray.ndim
4. ndarray 타입
- 타입 : 숫자, 문자열, 불린 등 모두 가능
- 숫자형의 경우 int, unsigned int, float이 있는데, 터 큰 숫자나 정밀도를 위한 complex 타입도 있다.
- ndarray 내의 테이터 타입은 같은 타입의 데이터만 가능하다. => 하나의 ndarray 객체에 int와 float가 같이 있을 수 없다!
ex)
가능 : [1,2,3]. ["바나나", "사과", "딸기"]. [True, False, True].
불가능 : [1, "장난감"]
- 데이터 타입이 다를 경우에는 용량이 큰 쪽으로 자동 형변환 된다.
array1 = np.array([1,2,'text'])
print(array1)
# print 결과값
# int 값이 문자열로 자동 형변환 된다.
['1', '2', 'test']- ndarray 내의 데이터 타입은 ndarray.dtype으로 확인.
5. ndarray 타입 변환
: astype()
- 변경을 원하는 타입을 astype()에 인자로 입력
- 대용량 데이터를 다룰때는 메모리 절약을 위해서 형변환을 고려하는 것이 좋다.
import numpy as np
# float 타입의 ndarray 선언
array1 = np.array([1.0, 2.0, 3.0])
# int 타입으로 형변환 예시1
array1_int = array1.astype("int32")
# int 타입으로 형변환 예시2
array1_int = array1.astype(np.int32)
6. list vs ndarry
import numpy as np
list1 = [1, 2, 3]
print('list1 type:', type(list1))
array1 = np.array(list1)
print('array1 type:',type(array1))- 위의 예시에서 list1은 python의 list 객체 이지만, 이 리스트를 np.array()를 이용하여 선언한 array1은 numpy.ndarray의 객체가 된다.
7. axis 축
: axis0, axis1, axis2로 부여되는데, 차원에 따라 axis가 다르게 부여된다.
8. ndarray를 편리하게 생성하기
(1) arange, zeros, ones
import numpy as np
# arange
np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
# zeros
np.zeros((3, 2), dtype='int32') #[[0 0], [0 0], [0 0]]
# ones
# dtype을 적어주지 않으면 float64가 default.
np.ones((3, 2)) # [[1. 1.], [1. 1.], [1. 1.]]
(2) 차원과 크기 변경 : reshape()
import numpy as np
# 1차원
array1d = np.range(10) # [0 1 2 3 4 5 6 7 8 9]
# 2차원으로 변경
array2d = array1d.reshape(2, 5) # [[0 1 2 3 4], [5 6 7 8 9]]- reshape()의 첫번째 인자에 -1을 넣으면 행의 길이를 알아서 유동적으로 만들어준다.
- 만약 위의 예시에서 길이가 10인 1차원 배열을 reshape(2, 4) 하여 열의 값을 4로 주게되면 10/4는 딱 떨어지지 않기 때문에 오류가 난다.
마찬가지로 reshape(2, 2)로 변경하려고 하면 [[0 1], [2 3]] 이후에 변경전의 데이터가 남아 있기 때문에 에러가 발생한다.
9. 인덱싱
: ndarray 내의 특정값을 가져오는 방법
(1) 단일값 추출
# 1차원
array1d = np.range(10)
array1d[3]
# 2차원
arrray2d = np.ones((3,2))
arrray2d[1,2] #[행, 열]- 대괄호안에 있는 숫자는 값이 아니라 인덱스 값을 의미한다.
- index는 0부터 시작. index -(마이너스)값은 뒤에서 부터 시작함.
ex) array[-1] 는 맨 뒤에서 첫번째 값.
(2) 슬라이싱
: 연속된 ndarray를 추출
# 1차원
array1d = np.range(10)
array1d[0:3] # index 0~2 까지의 값을 의미
array1d[3:] # index3부터 끝까지
# 2차원
array2d = np.ones((3,3))
array2d[0:2, 0:2]
array2d[:, :]
array2d[1:3, :]- array2d[0:2, 0:2]
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
(3) 팬시 인덱싱
: 슬라이싱과 유사하지만, 팬시 인덱싱은 index 리스트를 지정하여 이에 해당하는 ndarray를 반환함.
# 1차원
array1d = np.range(10) # [0 1 2 3 4 5 6 7 8 9]
array1d[[2,4,7]] # [2, 4, 7]
# 2차원
array2d = np.ones((3,3))
array2d[[0,1], 2]
array2d[[0,1]] # => array2d[[0,1], :] 과 같음.- array2d[[0,1], 2]
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
- array2d[[0,1]]
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
(4) 불린 인덱싱
: 조건에 맞는 인덱스를 찾아 ndarray를 반환.
array1d = np.range(start=0, strop=10)
array1d[array1d > 5] # array1d 값이 5보다 큰 것은? [6 7 8 9]'개발 일기라기 보단 메모장 > Python' 카테고리의 다른 글
| 파이썬 머신러닝을 위한 환경세팅 (0) | 2022.07.11 |
|---|---|
| 머신러닝공부 R vs Python 비교하기 (0) | 2022.07.11 |
| 머신러닝이란 무엇일까? (0) | 2022.07.11 |
| Mac Anaconda 설치 이후 터미널 실행시 가상환경 자동 시작 설정 해제하기 (0) | 2022.06.28 |
